Figure 1. Watch a five-minute video that introduces the main objectives, methods, and results of the Rogue Scores project.
Figure 2. A sample of tasks and models that use
Is Language Model Evaluation Reproducible, Comparable, and Correct?
The Rogue Scores project examines machine learning reproducibility with a systematic review of model evaluation using
A review of 2,834
These findings suggest 2,000+ language and vision papers report incorrect
Why are these results significant?
Rogue Scores is the largest machine learning reproducibility study to date. It discovers widespread evaluation integrity issues affecting thousands of papers published over two decades. The results affect the validity and interpretation of
Rouge , a widespread benchmark model evaluation metric. They suggest that major evaluation issues may exist throughout machine learning research.
Model Evaluation is Hard to Reproduce
Figure 3. Language model evaluations using
Open Sci. Collab. (2015)
Camerer et al. (2016)
Camerer et al. (2018)
Errington et al. (2021)
What percentage of
The Rogue Scores project assesses the reproducibility of
Reproducibility studies in other scientific fields like psychology and economics were able to reproduce between 39% (Open Science Collaboration, 2015) and 62% (Camerer et al., 2018) of published results. By comparison, only 20% of language model evaluations met the basic reproducibility criteria for
Does AI have a reproducibility problem?
Rogue Scores estimates that only 1 in 5
Rouge scores in peer-reviewed papers could be reproduced using details provided in papers and codebases. The reproduction rate of model evaluation usingRouge is much lower than comparable reproduction rates of results from other scientific fields.
Model Evaluation is Difficult to Compare
Figure 4. Language model evaluations with
How much do configuration differences affect reported
Rogue Scores measures
The Rogue Scores systematic review finds only 5% of papers list
Why does configuration variability matter?
Rogue Scores finds that
Rouge configuration differences can meaningfully affect model evaluation scores. However, most papers do not reportRouge configuration details. This means many models may be evaluated with different unreported configurations, making it challenging to separate legitimate modeling improvements from artificial configuration-related score variability.
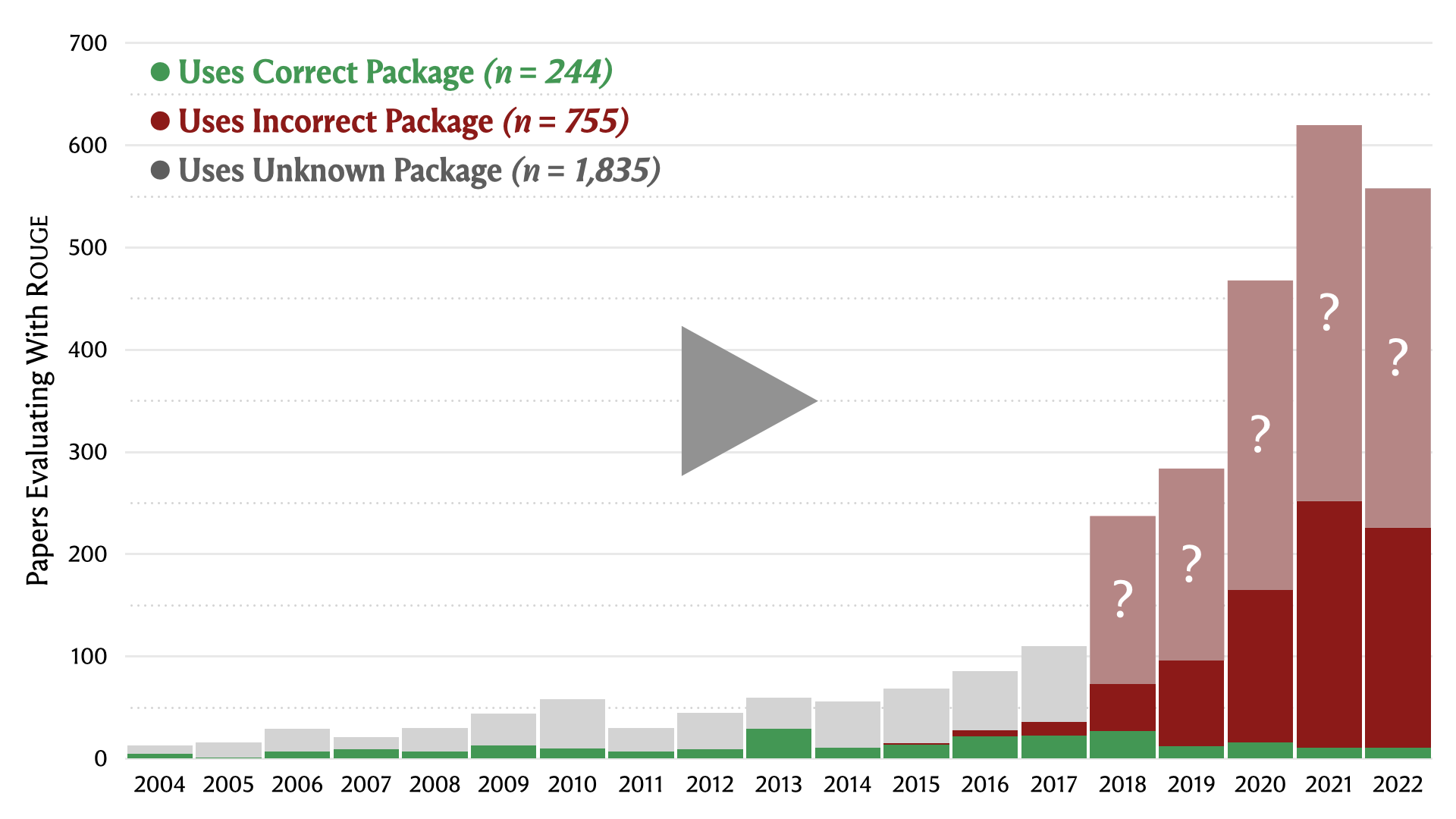
Model Evaluation is Frequently Incorrect
Figure 5. Language model evaluations with
Are
Rogue Scores identifies 17 ROUGE-1.5.5 reference implementation (Lin, 2004). For the first time, detailed model-output-level correctness testing is conducted for all 17 packages. This package testing process identifies only 1 out of 17 common packages used in peer-reviewed papers computes fully correct
The Rogue Scores systematic review finds 76% of papers with
How does this compare to other scientific errors?
Rogue Scores identifies errors in important evaluation software likely used in thousands of peer-reviewed papers. This kind of software error is unprecedented in scientific research and is likely the most significant and widespread research integrity issue to date in machine learning history.
Evaluation Case Study: Mistake of the Art
Figure 6. Any model can have state-of-the-art scores: just pick an incorrect
| State-of-the-Art Summarization Models | ||||
|---|---|---|---|---|
| R-1 | R-2 | R-L | ||
| Lead-3 (Simple Baseline) | 40.34 | 17.55 | 36.58 | Rogue-3 is Lead-3 re-evaluated with a peer-reviewed incorrect |
| T5 (Raffel et al., 2020) | 43.52 | 21.55 | 40.69 | |
| BART (Lewis et al., 2020) | 44.16 | 21.28 | 40.90 | |
| PEGASUS (Zhang et al., 2020) | 44.17 | 21.47 | 41.11 | |
| SIMCLS (Liu and Liu, 2021) | 46.67 | 22.15 | 43.54 | |
| BRIO (Liu et al., 2022) | 47.78 | 23.55 | 44.57 | |
| Rogue-3 (Incorrect Lead-3) | 73.89 | 55.80 | 73.89 | |
Could
In this evaluation case study, Rogue Scores uses nonstandard
This case study evaluates models for text summarization, a well-studied and competitive language generation task that uses
On the other hand, the incorrectly evaluated
Are all incorrect scores this extreme?
Rogue Scores uses an incorrect package that dramatically inflates scores by 20+
Rouge points. Not all incorrect packages have such obvious errors. Many have smaller or unpredictable errors, or errors that decrease scores. However, even small and subtle errors harm the integrity of the research record.
Learn More About Rogue Scores
Watch the Overview Video — View a five-minute video that summarizes the objectives, methods, and major findings of the Rogue Scores project.
Review the ACL 2023 Proceedings — Read a report on evaluation software errors found in the proceedings of ACL 2023, a major natural language processing conference.
Read the ACL 2023 Paper — Learn more about the systematic review, configuration sensitivity experiments, and
Rouge package testing methods and results.Consult the Software Guide — Read about specific errors discovered in common Rouge software packages used for language model evaluation in peer-reviewed papers.(Software guide will be available soon.) Follow the Reproducibility Guide — Follow a step-by-step guide for recreating all of the figures and tables in the Rogue Scores paper using the code and data release.
Download the Code & Data — Experiment with
Rouge packages and configurations used in peer-reviewed papers and examine the systematic review dataset.